A hybrid approach combining on-device and cloud AI processing is emerging as the key to building sustainable, privacy-conscious applications at scale. This architecture leverages local computing power for immediate and simple tasks while reserving cloud resources for complex operations, enabling truly unlimited AI features without compromising economics or user privacy.
AI features are rapidly becoming table stakes for applications, but there's a growing challenge with scale. Even as cloud AI costs decrease, the fundamental architecture of today's AI applications creates real constraints that manifest in unexpected ways: "unlimited" plans that aren't truly unlimited, byzantine pricing tiers that confuse users, and applications that struggle to maintain their promise as usage grows.
Just as browsers leverage device hardware alongside cloud resources to provide seamless experiences, AI applications don't need to push everything to the cloud. Sometimes it's about using the right tool for the right job, rather than treating LLMs as a one-size-fits-all solution. When Exa.ai's Twitter wrapped feature went viral, they discovered this firsthand. Their solution was to adopt a hybrid model where a smaller, more efficient model handled lower-priority requests, while reserving their more powerful LLMs for critical tasks. This wasn't just clever engineering – it was necessary for scalability.
When Exa.ai's Twitter wrapped went viral, they shifted to a hybrid approach using smaller models like GPT-4o-mini to manage costs and scale
This wasn't an isolated incident, but a signal of a broader architectural shift. Before building Slipbox, our team's experience with various meeting assistants revealed to us that traditional cloud-first approaches, while powerful and convenient, created an inherent tension between capability and scalability. The fundamental question wasn't about building better features – it was about reimagining how AI applications could grow sustainably while maintaining their promise to users.
Our answer emerged in the form of a hybrid agentic architecture. Where traditional approaches defaulted to pushing and running everything in the cloud, we recognized that intelligent systems need the flexibility to leverage both local and cloud resources effectively. By building Slipbox with on-device agents that can seamlessly coordinate with more powerful cloud systems, we created an architecture that can dynamically adapt to user needs while maintaining sustainable economics. This wasn't just an optimization – it represented a fundamental shift in how AI applications could deliver on their promises at scale.
In this post, we'll break down our journey to this architecture, the technical decisions that made it possible, and why we believe this hybrid approach represents the future of AI applications. There are many other factors—such as legal concerns like getting consent from attendees, how meetings are the key for personalization at scale, and dealing with hallucinations—that we will cover in sequel blogs.
The Foundation: Speech to Text
Our journey to find the right transcription solution was more complex than we initially expected. Like many startups, we started by evaluating Recall.ai, which offers an elegant solution for bootstrapping a meeting bot. The platform handles all the complexity of joining calls and managing transcriptions, making it an attractive starting point. However, two issues emerged: the B2B pricing model didn't align with our unit economics, and relying on a third party for such a fundamental feature felt risky for long-term sustainability.
This led us to explore specialized transcription providers like Assembly and Deepgram. While they offered impressive accuracy and additional features like speaker diarization, the cost structure remained problematic. With our goal of providing unlimited transcription to users, these services would consume 30-40% of our margins. This would severely limit our ability to invest in other features and maintain competitive pricing.
The breakthrough came when we started experimenting with running Whisper on the device. Initial results were promising, but real-time transcription presented significant challenges. Through careful optimization and tuning, we eventually achieved a Word Error Rate (WER) of approximately 11% for real-time streaming transcription on M-series chips – a feat we can deliver consistently even on an M2 MacBook Air. When compared to cloud providers' benchmarks (figure 1), this performance demonstrates that local processing can rival cloud solutions with with zero marginal cost, allowing us to offer truly unlimited transcription.
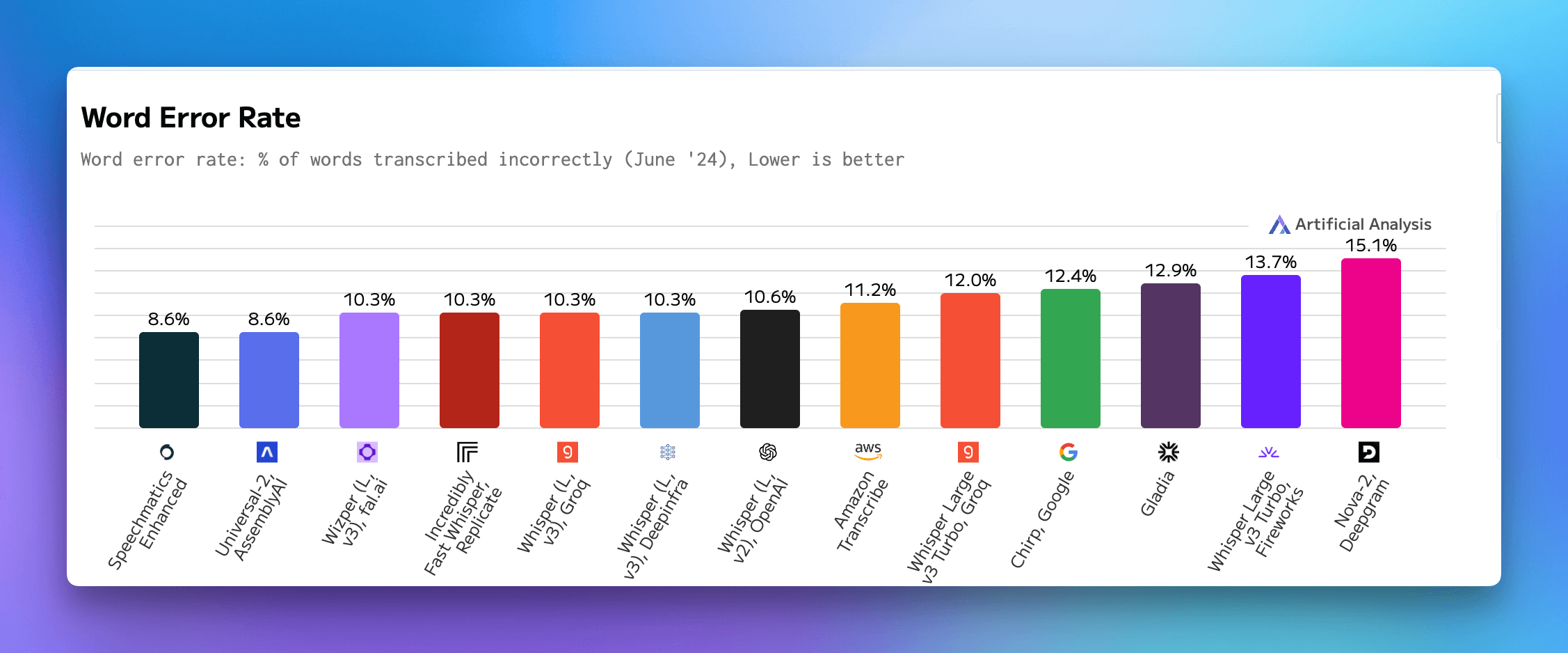
Word Error Rate (WER) benchmarks comparing various cloud providers' speech-to-text services
This technical choice has significant implications for our users. We've observed a common pattern in the meeting assistant space: platforms advertise "unlimited" transcription, but often with hidden constraints. Some limit storage duration, while others start with attractive pricing (say, $10/month) only to raise rates significantly (to $18 or more) once the unit economics become unsustainable. By processing transcripts locally, we can offer genuinely unlimited transcription without these asterisks or future price hikes – a promise we can sustainably keep.
This approach also unlocked new possibilities for real-time intelligence (read more about it here). Local processing enables our agents to monitor conversations and provide immediate cues to users without the latency of cloud round-trips. Perhaps most importantly, it gives users complete control over their data – sensitive meeting content doesn't have to leave the device unless specifically requested, transforming how users can engage with AI assistance while maintaining privacy.
The Engine Room: Small vs Large Language Models
Finding the Right Balance
Our approach to model selection evolved similarly. For cloud operations, we started with OpenAI and gradually expanded to include Anthropic, Gemini, and Groq – each serving specific use cases where they excel. But the more interesting challenge was choosing the right Small Language Model (SLM) for local processing. This decision became particularly relevant as Apple began investing heavily in on-device AI capabilities (https://www.theinformation.com/articles/apple-is-working-on-ai-chip-with-broadcom). The performance improvements we've seen with each generation of M-series chips have been remarkable, making local AI processing increasingly viable with each new generation of chips (Figure 3).
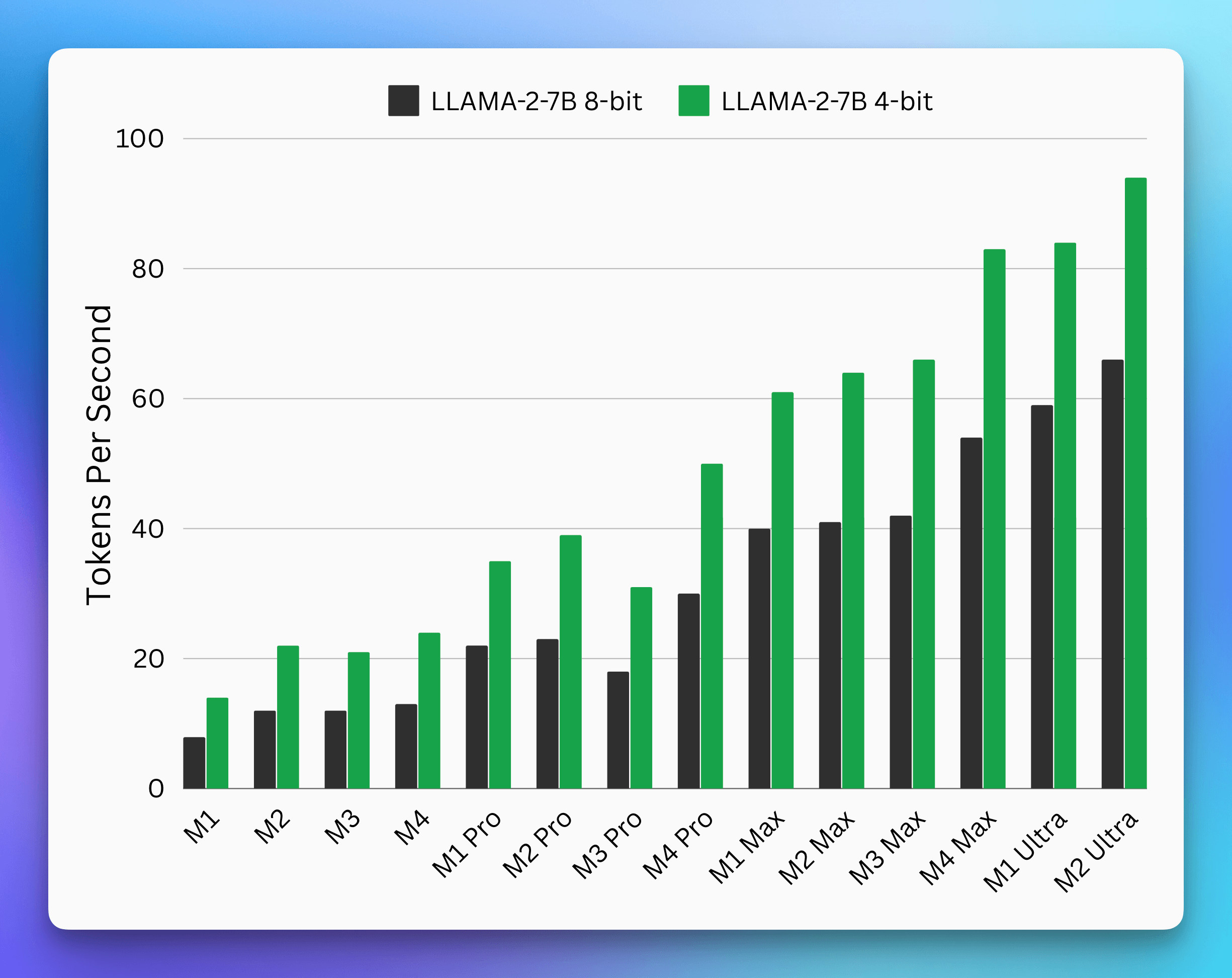
Performance improvements of LLAMA-2-7B running on Apple Silicon chips over time, showing significant speed gains with each generation
The Rise of Smaller, Smarter Models
What's particularly exciting is how quickly SLMs are evolving. The latest Qwen 2.5-3B models are achieving benchmark scores that seemed impossible just a year ago. To put this in perspective: these compact models are now scoring above 65 on the MMLU benchmark – a feat that even the massive LLaMA-65B model couldn't achieve in early 2023.
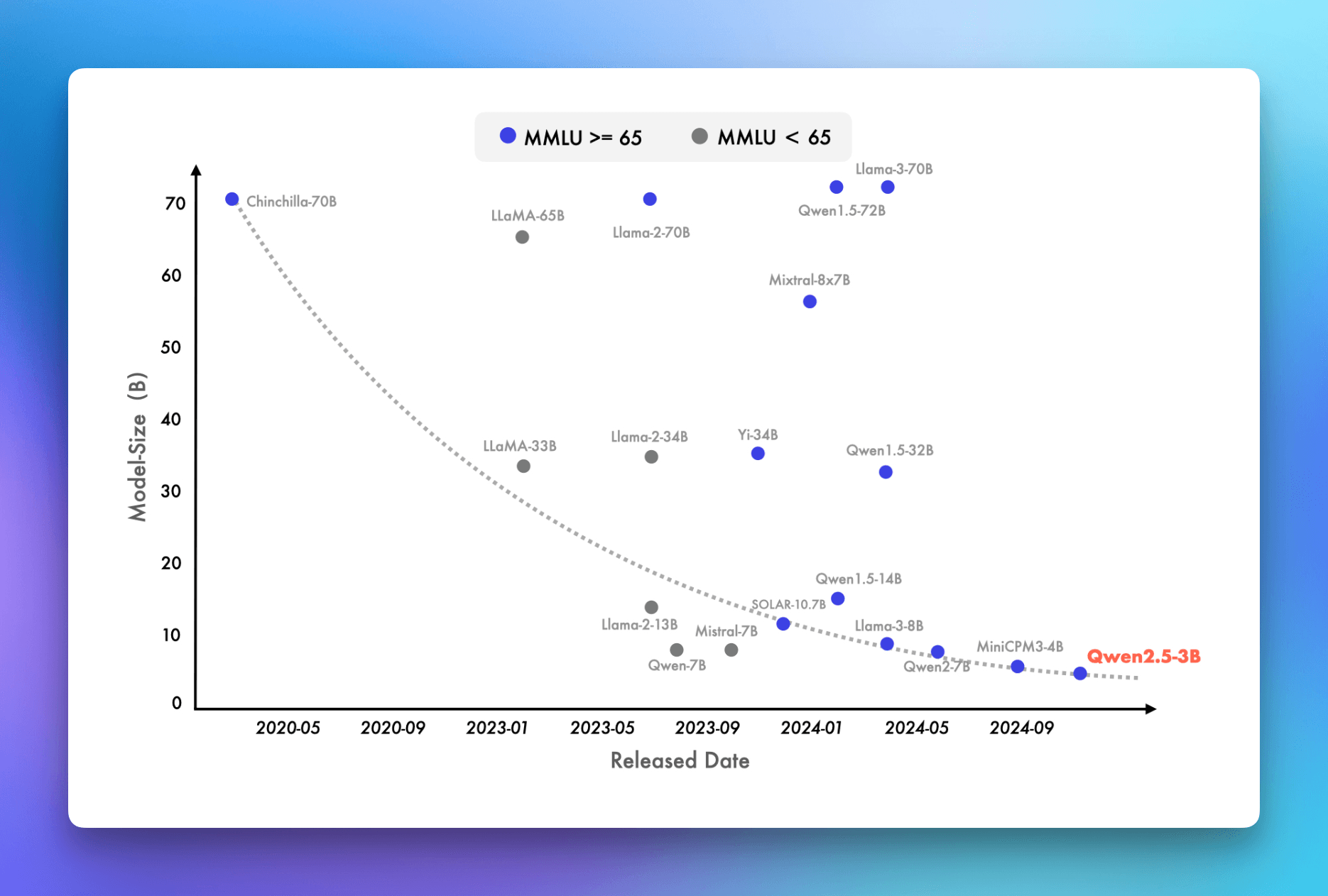
MMLU benchmark improvements showing enhanced reasoning and problem-solving capabilities in smaller models
This rapid progress in SLM capabilities isn't just a technical achievement – it's a glimpse of the future. As these smaller models become more capable, the possibility of delivering sophisticated AI features directly on users' devices becomes increasingly realistic. For Slipbox, this means we can offer more responsive, private, and cost-effective features without compromising on quality.
Industry Validation and Research
We're not alone in recognizing the potential of hybrid architectures. Both academia and industry are increasingly exploring this approach, validating our technical decisions with Slipbox.
A compelling example from industry is MotherDuck, which applies hybrid thinking to databases. By intelligently combining local and cloud computing power, they've shown how hybrid architectures can deliver better performance and economics than pure cloud solutions (read more here) . Their success in database technology parallels what we're seeing in AI – local compute is an underutilized resource that, when properly leveraged, can transform application architecture.
The academic research reinforces this direction. Recent papers have explored various aspects of hybrid AI architectures, demonstrating how SLMs can effectively complement larger models rather than compete with them. This growing body of research and real-world implementation suggests we're part of a broader movement toward more efficient, sustainable AI architectures.
More Readings:
Our Architecture in Practice
At Slipbox, we've implemented our hybrid architecture through a system of coordinated agents. Local agents run directly on the user's device, handling transcription and basic AI features using SLMs. When more complex processing is needed, these agents seamlessly pass context to our cloud infrastructure, where more powerful LLMs take over. We observed a 50% savings with SLMs being in the loop for agentic operations with little to no impact on quality for the end user.
The same principle applies in the cloud: our cloud agents use smaller models like Claude Haiku and GPT-4o-mini to filter and process simpler requests, only engaging larger models when necessary. This cascading approach ensures we're using the right tool for each task while maintaining efficiency.
Leveraging Existing Resources
One of our key insights was recognizing the untapped potential in our users' Mac devices. Modern Macs pack significant computing power that users have already paid for – power that often sits idle. By running a native application, we can tap into this resource to process sensitive data locally, provide immediate responses, and optimize cloud usage. This approach doesn't just save costs – it fundamentally improves the user experience by keeping private data local and allowing applications to deliver more value to the user
One caveat here is that Slipbox also needs to intelligently unload resources when it's not in use, SLMs, though “small”, take up a significant amount of memory when loaded, local applications must minimize their footprint.
Balancing Constraints and Opportunities
Building this hybrid architecture required us to navigate several technical challenges. Small Language Models, while powerful, have inherent limitations in processing large amounts of text and can struggle with repetition, especially in quantized versions. Additionally, while local inference provides privacy benefits, it can't match the raw processing speed of cloud systems. Hardware variability adds another layer of complexity – what works smoothly on a high-end Mac might strain an older device.
Given these constraints, Slipbox needs to dynamically adapt to each device's capabilities, routing tasks between local and cloud processing based on complexity, hardware and privacy constraints. For instance, using SLMs for non-visible like classification, filtering, content moderation, and simple tasks like search and template generation, and routing to cloud agents for critical features like summarization and online data integration.
This strategy has proven effective, and with the rapid pace of SLM development, we expect these limitations to diminish over time. The key is finding the right balance between local and cloud processing while maintaining a seamless user experience.
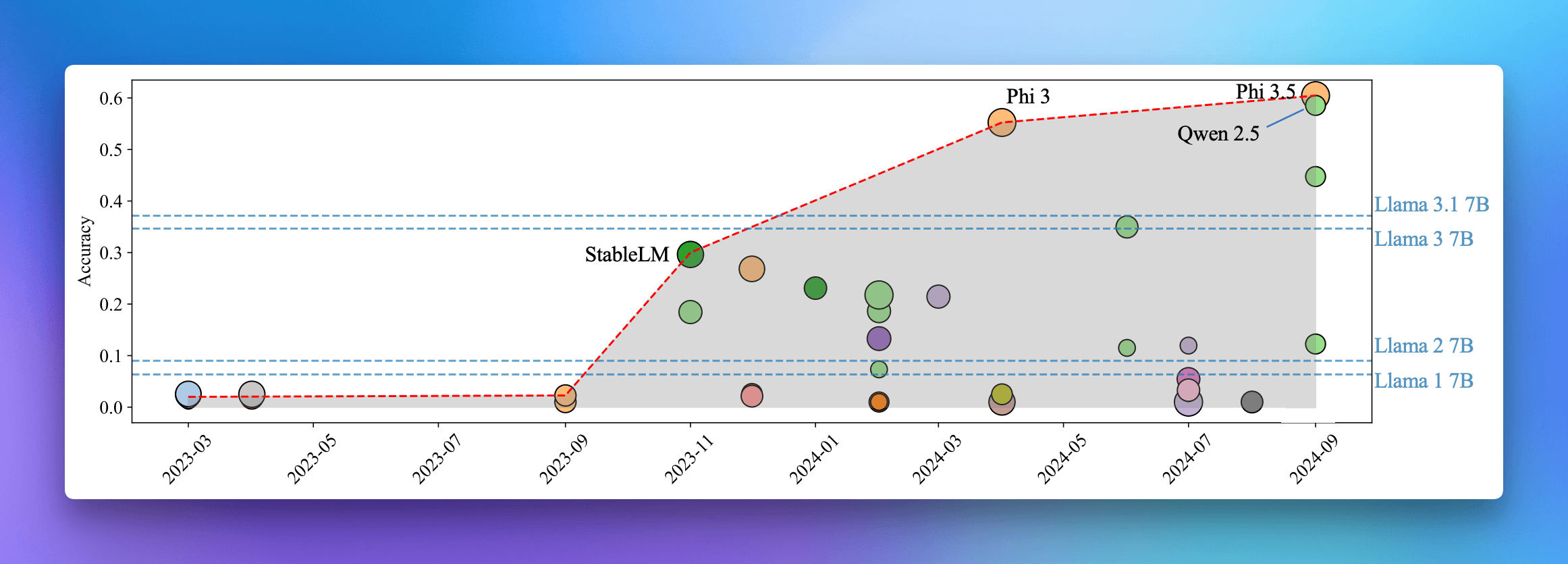
Significant improvements in Small Language Models' performance on math, problem-solving, and reasoning tasks compared to early 2023
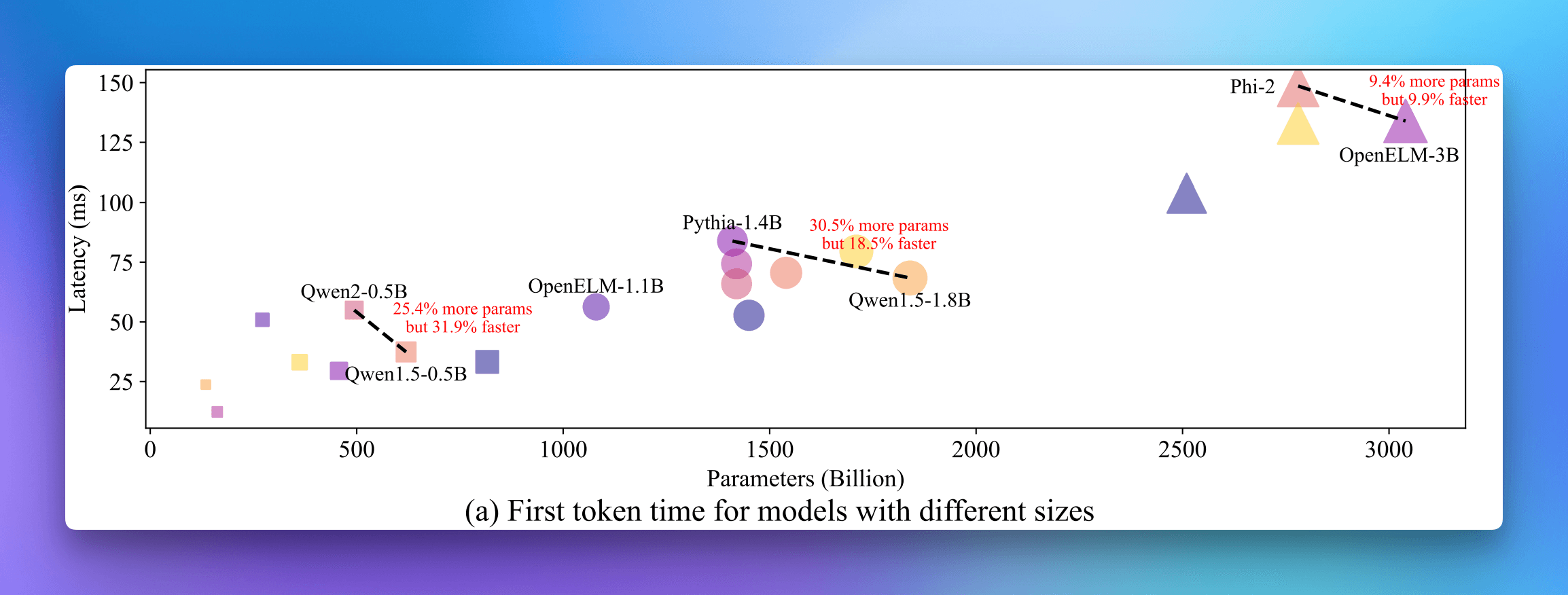
First token time improvements showing Qwen2-0.5's superior performance despite having only 25% of the parameters
The Hybrid Future of AI Applications
While AI costs are decreasing, total spending will keep growing as usage expands - just as CPU, memory, and storage costs followed the same pattern, where decades of price reduction led to higher consumption rather than lower total costs. The future of AI applications won't be built entirely in the cloud or entirely on-device – it will emerge from the combination of both. Our journey with Slipbox's hybrid architecture has shown that this approach isn't just technically feasible, it's economically essential for building sustainable applications with AI. From achieving 12% WER with on-device transcription (down to 8.8% ± 1.5% since this blog was published) to leveraging SLMs for efficient processing, though early, we've demonstrated that local compute, when properly architected, can transform what's possible.
The rapid evolution of on-device compute capabilities, particularly with chips like Apple Silicon, is opening new possibilities and it's clear that Apple is doubling down on running models on device. When we combine this local processing power with cloud-based LLMs, we can create experiences that are both more personal and more powerful. Local agents can handle privacy-sensitive tasks and immediate responses, while cloud agents can tackle complex processing – all while maintaining favorable unit economics.
Looking ahead, we see several exciting possibilities. The emergence of more capable SLMs – now achieving MMLU scores above 65 – shows how quickly on-device AI is evolving. The ability to fine-tune personal SLMs that stay on-device could revolutionize how AI assistants learn and adapt to individual users. Frameworks like MLX are making it possible to fine-tune and train SLMs efficiently directly on the user's device. Meanwhile, improvements in model compression and quantization are continuously expanding what's possible on-device. This isn't just about technical capabilities; it's about fundamentally reimagining how AI applications can scale sustainably.
But perhaps most importantly, this hybrid approach gives users what they've been asking for: AI assistants that are truly personal, respectful of privacy, and unlimited in their availability. No more asterisks on "unlimited" plans, no more compromises between capability and cost. We believe this architecture will power the next generation of AI applications – not because it's technically impressive, but because it's what sustainable, user-centric AI requires.
At Slipbox, we're just scratching the surface of what's possible with hybrid architecture. As both local and cloud-based models continue to evolve, we're excited to push the boundaries of what an AI assistant can be – all while staying true to our commitment to privacy, personalization, and sustainable economics.
